Generating Structured Outputs from LLMs
In my previous project Sakha, I needed to generate a lot of structured outputs so the chatbot could function like an agent — using tools, recalling memories, and managing context effectively. I achieved this through langchain’s inbuilt structured output implementation(wrapper for API’s that support it) :
llm.with_structured_output(ResponseStructure).invoke(prompt)This made me wonder: How does it happen? Do I need to retrain the model to reliably produce valid structured text?
It turns out — no, you don’t.
In this post, I’ll share what I learned about how structured output generation actually works in modern LLMs.
Why Structured Output Matters
When your application needs reliable JSON, SQL, or other formal languages from an LLM, validity is critical. Even a single missing bracket in generated JSON — like {"name": "John" instead of {"name": "John"} — can break downstream systems.
Naively prompting a model to “generate JSON” often leads to malformed outputs or subtle syntax errors. To make structured generation reliable, we need a way to enforce valid structure while decoding.
Why Prompting (and Re-prompting) Isn’t Enough
A common workaround is to simply “prompt better” — for example, asking the model to strictly output valid JSON or to fix invalid output and try again. While this works sometimes, it’s fundamentally unreliable at scale.
Here’s why:
- Probabilistic outputs — even with careful instructions, the model samples from a distribution, so small randomness can break structure.
- Error amplification — if a model generates slightly invalid text, a re-prompt often leads to compounding errors or over-correction.
- Inefficiency — detecting and fixing invalid outputs adds latency and cost, especially when multiple re-prompts are needed.
- No structural guarantees — the model may “look” like it’s following instructions but still produce text that only appears valid (e.g., unbalanced brackets or escaped quotes).
Prompt engineering improves likelihood, not certainty. Grammar-constrained decoding, in contrast, enforces correctness by design — the model literally cannot emit an invalid token.
Constrained Decoding: The Basic Idea
How can we guarantee valid model outputs? Enter constrained decoding.
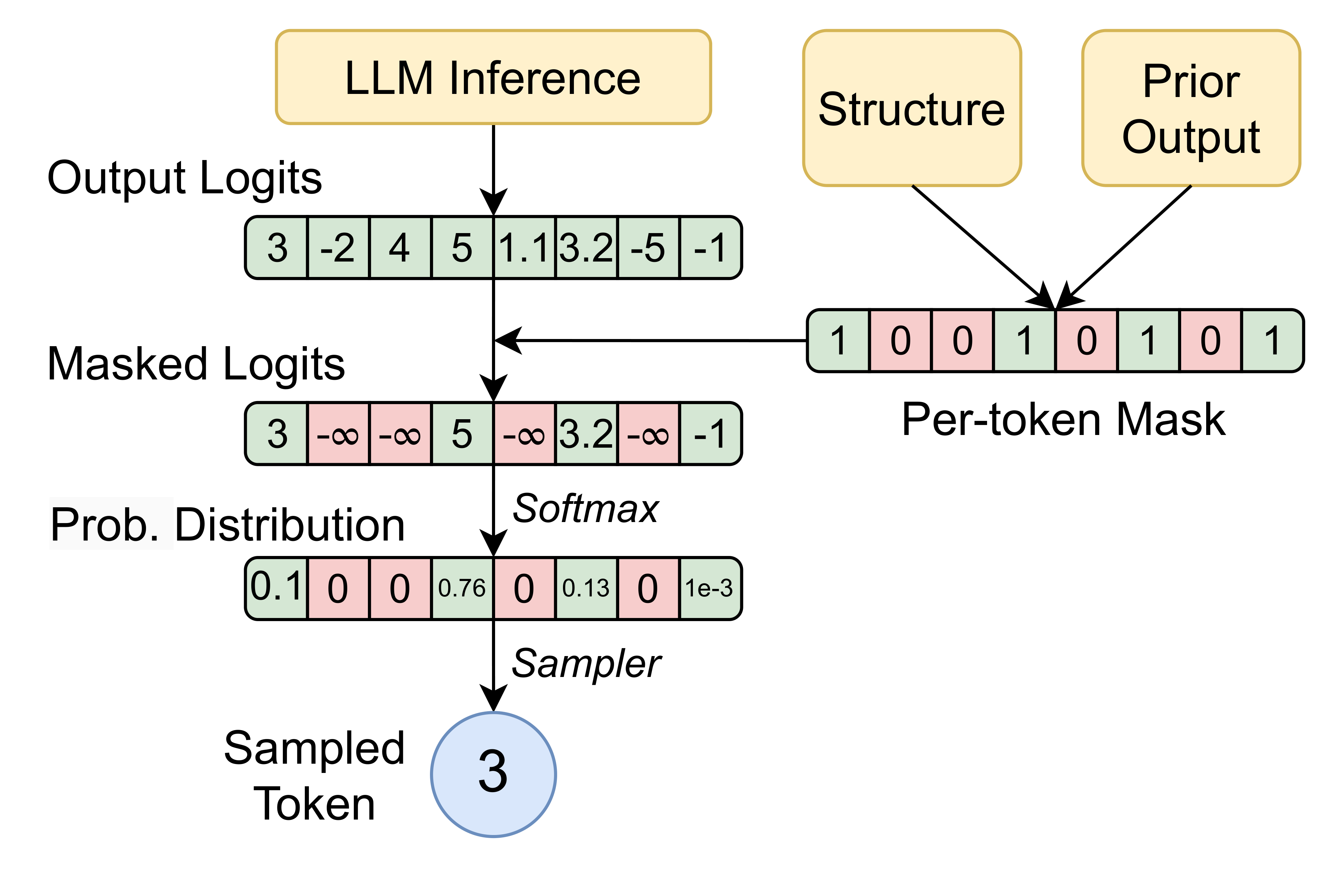
During generation, an LLM predicts a probability distribution (logits) over all possible next tokens at each step. Constrained decoding applies a mask to this distribution — blocking tokens (by setting their logits to -∞) that would violate a desired structure.
For example, it can prevent the model from generating a } before a matching {.
By restricting the model to only valid tokens, we ensure syntactic correctness and drastically reduce the search space for valid sequences.
There are many ways to constrain an LLM’s output:
- Grammar Constraints – Enforce structural rules, such as requiring output to follow a JSON schema or match a regex pattern.
- Lexical Constraints – Control word choice, e.g., forbidding certain tokens or forcing specific words to appear.
- Semantic Constraints – Limit the meaning of outputs, e.g., ensuring numeric values stay within a range (0–100) or that a list of values sums to 1.
Note: A rule like “color must be in [red, yellow, green]” is not a semantic constraint but a grammar constraint—the model doesn’t need to understand meaning, it just has to choose from a fixed set of allowed tokens.
These are just a few examples—many other types of constraints can be applied depending on the use case.
Grammar-Constrained Decoding
Grammar-constrained decoding enforces a complete structural definition of what counts as valid output.
This is achieved using a Context-Free Grammar (CFG) — a formal set of production rules that describe how valid strings in a language (such as JSON or SQL) can be constructed. In essence, the grammar specifies which tokens can legally follow which, ensuring that the output remains structurally correct from start to finish.
Note: CFG vs. CSG
- Context-Free Grammar (CFG): Rules apply independently of surrounding context.
- Context-Sensitive Grammar (CSG): Rules depend on context — for example, plural agreement in natural language (“this” vs. “these”).
Because CFGs encode full syntactic rules, grammar-constrained decoding enables models to produce valid outputs by construction — without needing post-generation validation.
Why We Don’t Need to Retrain the Model
A key insight is that pretrained LLMs already know how to produce structured text — they’ve seen plenty of JSON, code, and markup during training.
The challenge isn’t teaching them structure — it’s enforcing that structure during sampling. By constraining token choices based on grammar rules, we can guide the model toward valid outputs without changing its weights.
This makes structured generation fast, general, and free of retraining overhead.
Open Libraries That Support Grammar-Constrained Decoding
Several open libraries now implement grammar-constrained decoding in practice:
XGrammar — integrates grammar checks directly into the decoding loop, updating valid token masks as each token is generated. It’s efficient and works well with open-weight models run locally (e.g., vLLM or MLC).
LLGuidance — re-parses the partial output after every generation step using the provided grammar to determine valid next tokens. It supports API-based black-box models like OpenAI’s but can be slower due to repeated parsing overhead.
Outlines — uses a grammar-aware tokenizer and validates tokens against the grammar during generation. It strikes a balance between control and ease of integration, suitable for both open and hosted models.
Each library applies the same principle — restrict the next-token choices according to grammar rules — but differs in where it enforces the constraint (inside the decoding loop vs via external parsing).
Why Grammar-Constrained Decoding Can Still Fail
Even with grammar enforcement, structured output isn’t foolproof. Failures can still occur for several reasons:
- Semantic errors — the generated output may be valid according to the grammar but still nonsensical
- Incomplete grammars — hand-written grammars might miss certain valid constructs, causing otherwise correct outputs to be rejected or malformed ones to slip through.
- Performance trade-offs — for complex grammars, generating masks or re-parsing at each step can slow decoding significantly.
- Tokenization mismatches — when model tokenization doesn’t align perfectly with grammar tokens, valid sequences can become unreachable or invalid.
In short, grammar constraints guarantee syntax, not semantics — they keep the form right, but not always the meaning.
Final Thoughts
Generating structured outputs from LLMs doesn’t require retraining — it requires smarter decoding. Grammar-constrained decoding offers a principled way to ensure syntactic validity while leveraging pretrained knowledge of structure.